Running a model comparable to o3 on a 24GB Mac Mini is absolutely wild. Seems like yesterday the idea of running frontier (at the time) models locally or on a mobile device was 5+ years out. At this rate, we'll be running such models in the next phone cycle.
It only seems like that if you haven't been following other open source efforts. Models like Qwen perform ridiculously well and do so on very restricted hardware. I'm looking forward to seeing benchmarks to see how these new open source models compare.
Nah, these are much smaller models than Qwen3 and GLM 4.5 with similar performance. Fewer parameters and fewer bits per parameter. They are much more impressive and will run on garden variety gaming PCs at more than usable speed. I can't wait to try on my 4090 at home.
There's basically no reason to run other open source models now that these are available, at least for non-multimodal tasks.
Qwen3 has multiple variants ranging from larger (230B) than these models to significantly smaller (0.6b), with a huge number of options in between. For each of those models they also release quantized versions (your "fewer bits per parameter).
I'm still withholding judgement until I see benchmarks, but every point you tried to make regarding model size and parameter size is wrong. Qwen has more variety on every level, and performs extremely well. That's before getting into the MoE variants of the models.
The benchmarks of the OpenAI models are comparable to the largest variants of other open models. The smaller variants of other open models are much worse.
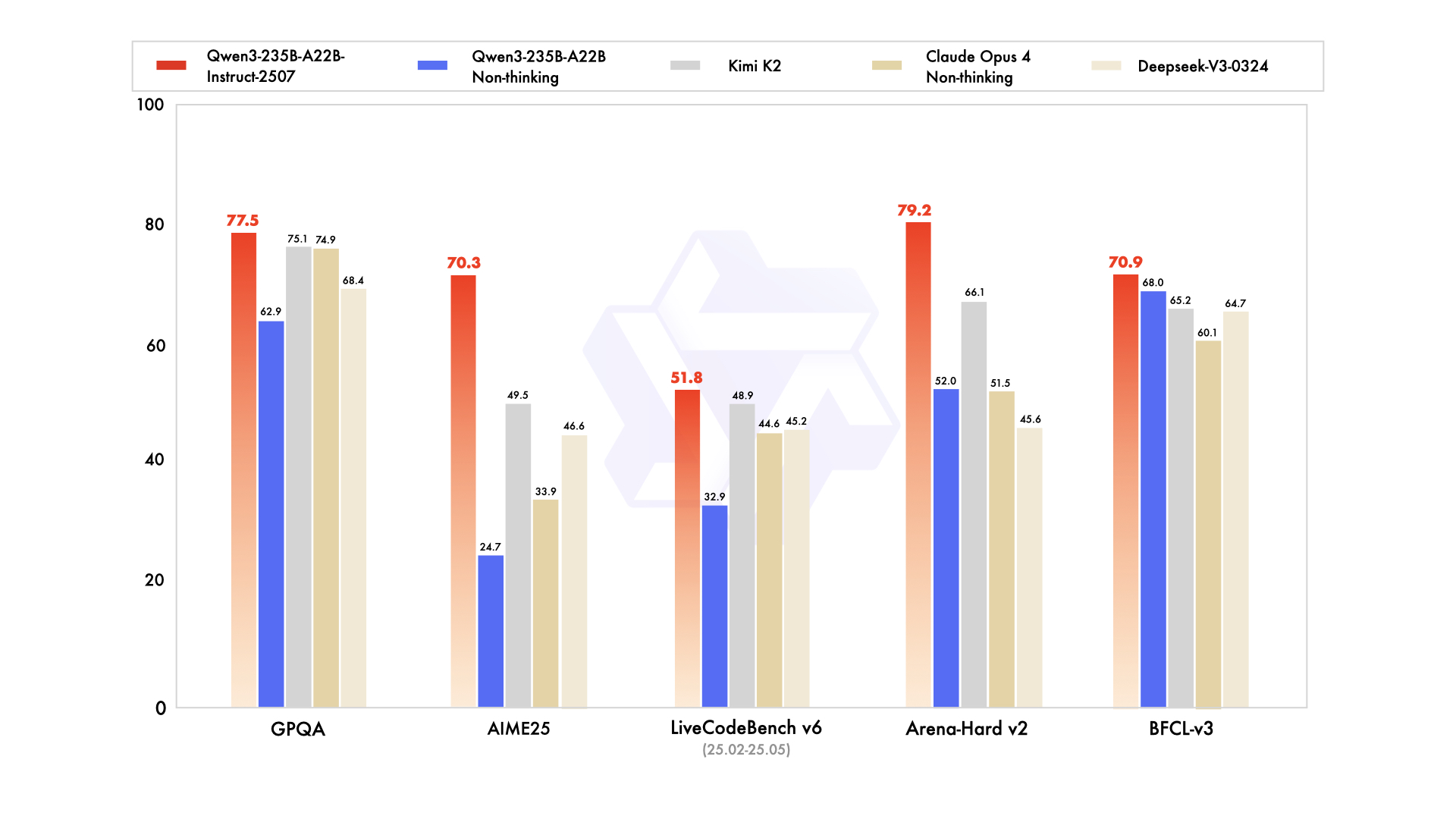
With all due respect, you need to actually test out Qwen3 2507 or GLM 4.5 before making these sorts of claims. Both of them are comparable to OpenAI's largest models and even bench favorably to Deepseek and Opus: https://cdn-uploads.huggingface.co/production/uploads/62430a...
It's cool to see OpenAI throw their hat in the ring, but you're smoking straight hopium if you think there's "no reason to run other open source models now" in earnest. If OpenAI never released these models, the state-of-the-art would not look significantly different for local LLMs. This is almost a nothingburger if not for the simple novelty of OpenAI releasing an Open AI for once in their life.
I'd really wait for additional neutral benchmarks, I asked the 20b model on low reasoning effort which number is larger 9.9 or 9.11 and it got it wrong.
They have worse scores than recent open source releases on a number of agentic and coding benchmarks, so if absolute quality is what you're after and not just cost/efficiency, you'd probably still be running those models.
Let's not forget, this is a thinking model that has a significantly worse scores on Aider-Polyglot than the non-thinking Qwen3-235B-A22B-Instruct-2507, a worse TAUBench score than the smaller GLM-4.5 Air, and a worse SWE-Bench verified score than the (3x the size) GLM-4.5. So the results, at least in terms of benchmarks, are not really clear-cut.
From a vibes perspective, the non-reasoners Kimi-K2-Instruct and the aforementioned non-thinking Qwen3 235B are much better at frontend design. (Tested privately, but fully expecting DesignArena to back me up in the following weeks.)
OpenAI has delivered something astonishing for the size, for sure. But your claim is just an exaggeration. And OpenAI have, unsurprisingly, highlighted only the benchmarks where they do _really_ well.
So far I have mixed impressions, but they do indeed seem noticeably weaker than comparably-sized Qwen3 / GLM4.5 models. Part of the reason may be that the oai models do appear to be much more lobotomized than their Chinese counterparts (which are surprisingly uncensored). There's research showing that "aligning" a model makes it dumber.
The censorship here in China is only about public discussions / spaces. You cannot like have a website telling you about the crimes of the party. But downloading some compressed matrix re-spouting the said crimes, nobody gives a damn.
We seem to censor organized large scale complaints and viral mind virii, but we never quite forbid people at home to read some generated knowledge from an obscure hard to use software.
On the subject of who has a moat and who doesn't, it's interesting to look the role of patents in the early development of wireless technology. There was WWI, and there was WWII, but the players in the nascent radio industry had serious beef with each other.
I imagine the same conflicts will ramp up over the next few years, especially once the silly money starts to dry up.
Right? I still remember the safety outrage of releasing Llama. Now? My 96 GB of (V)RAM MacBook will be running a 120B parameter frontier lab model. So excited to get my hands on the MLX quants and see how it feels compared to GLM-4.5-air.
I feel like most of the safety concerns ended up being proven correct, but there's so much money in it that they decided to push on anyway full steam ahead.
AI did get used for fake news, propaganda, mass surveillance, erosion of trust and sense of truth, and mass spamming social media.
in that era, OpenAI and Anthropic were still deluding themselves into thinking they would be the "stewards" of generative AI, and the last US administration was very keen on regoolating everything under the sun, so "safety" was just an angle for regulatory capture.
Oh absolutely, AI labs certainly talk their books, including any safety angles. The controversy/outrage extended far beyond those incentivized companies too. Many people had good faith worries about Llama. Open-weight models are now vastly more powerful than Llama-1, yet the sky hasn't fallen. It's just fascinating to me how apocalyptic people are.
I just feel lucky to be around in what's likely the most important decade in human history. Shit odds on that, so I'm basically a lotto winner. Wild times.
ah, but that begs the question: did those people develop their worries organically, or did they simply consume the narrative heavily pushed by virtually every mainstream publication?
the journos are heavily incentivized to spread FUD about it. they saw the writing on the wall that the days of making a living by producing clickbait slop were coming to an end and deluded themselves into thinking that if they kvetch enough, the genie will crawl back into the bottle. scaremongering about sci-fi skynet bullshit didn't work, so now they kvetch about joules and milliliters consumed by chatbots, as if data centers did not exist until two years ago.
likewise, the bulk of other "concerned citizens" are creatives who use their influence to sway their followers, still hoping against hope to kvetch this technology out of existence.
honest-to-God yuddites are as few and as retarded as honest-to-God flat earthers.
Lol. To be young and foolish again. This covid laced decade is more of a placeholder. The current decade is always the most meaningful until the next one. The personal computer era, the first cars or planes, ending slavery needs to take a backseat to the best search engine ever. We are at the point where everyone is planning on what they are going to do with their hoverboards.
The slavery of free humans is illegal in America, so now the big issue is figuring out how to convince voters that imprisoned criminals deserve rights.
Even in liberal states, the dehumanization of criminals is an endemic behavior, and we are reaching the point in our society where ironically having the leeway to discuss the humane treatment of even our worst criminals is becoming an issue that affects how we see ourselves as a society before we even have a framework to deal with the issue itself.
What one side wants is for prisons to be for rehabilitation and societal reintegration, for prisoners to have the right to decline to work and to be paid fair wages from their labor. They further want to remove for-profit prisons from the equation completely.
What the other side wants is the acknowledgement that prisons are not free, they are for punishment, and that prisoners have lost some of their rights for the duration of their incarceration and that they should be required to provide labor to offset the tax burden of their incarceration on the innocent people that have to pay for it. They also would like it if all prisons were for-profit as that would remove the burden from the tax payers and place all of the costs of incarceration onto the shoulders of the incarcerated.
Both sides have valid and reasonable wants from their vantage point while overlooking the valid and reasonable wants from the other side.
I do not think you can equate making prisoners work with slavery. Other countries do the same, and it is not regarded as slavery in general.
If people were sold into slavery as a punishment (so they became some one else's property) as some ancient societies did, then that would clearly be slavery.
The most shocking thing about prisons in the US is how common prison rape is, and the extent to which it seems to be regarded as a joke. The majority of rapes in the US are prison rapes. How can that not be anything but an appalling problem?
Rape is also something slaves are casually subject to in most slave societies. It was definitely accept that Roman slave owners were free to rape men, women and children they owned.
The US Constitution's 13th Amendment abolishing slavery specifically allows it for convicted people. [1]
You'll see from the definition of a "slave" [2] that prisoner labor specifically fits the definition of a slave, hence why the constitution makes an exception for it.
I think his point is that slavery is not outlawed by the 13th amendment as most people assume (even the Google AI summary reads: "The 13th Amendment to the United States Constitution, ratified in 1865, officially abolished slavery and involuntary servitude in the United States.").
However, if you actually read it, the 13th amendment makes an explicit allowance for slavery (i.e. expressly allows it):
"Neither slavery nor involuntary servitude, *except as a punishment for crime whereof the party shall have been duly convicted*" (emphasis mine obviously since Markdown didn't exist in 1865)
Prisoners themselves are the ones choosing to work most of the time, and generally none of them are REQUIRED to work (they are required to either take job training or work).
They choose to because extra money = extra commissary snacks and having a job is preferable to being bored out of their minds all day.
That's the part that's frequently not included in the discussion of this whenever it comes up. Prison jobs don't pay minimum wage, but given that prisoners are wards of the state that seems reasonable.
I have heard anecdotes that the choice of doing work is a choice between doing work and being in solitary confinement or becoming the target of the guards who do not take kindly to prisoners who don't volunteer for work assignments.
Yeah, China is e/acc. Nice cheap solar panels too. Thanks China. The problem is their ominous policies like not allowing almost any immigration, and their domestic Han Supremacist propaganda, and all that make it look a bit like this might be Han Supremacy e/acc. Is it better than wester/decel? Hard to say, but at least the western/decel people are now starting to talk about building power plants, at least for datacenters, and things like that instead of demanding whole branches of computer science be classified, as they were threatening to Marc Andreessen when he visited the Biden admin last year.
I wish we had voter support for a hydrocarbon tax, though. It would level out the prices and then the AI companies can decide whether they want to pay double to burn pollutants or invest in solar and wind and batteries
Qwen3 Coder is 4x its size! Grok 3 is over 22x its size!
What does the resource usage look like for GLM 4.5 Air? Is that benchmark in FP16? GPT-OSS-120B will be using between 1/4 and 1/2 the VRAM that GLM-4.5 Air does, right?
It seems like a good showing to me, even though Qwen3 Coder and GLM 4.5 Air might be preferable for some use cases.
When people talk about running a (quantized) medium-sized model on a Mac Mini, what types of latency and throughput times are they talking about? Do they mean like 5 tokens per second or at an actually usable speed?
After considering my sarcasm for the last 5 minutes, I am doubling down. The government of the United States of America should enhance its higher IQ people by donating AI hardware to them immediately.
This is critical for global competitive economic power.
higher IQ people <-- well you have to prove that first, so let me ask you a test question to prove them: how can you mix collaboration and competition in society to produce the optimal productivity/conflict ratio ?
Generation is usually fast, but prompt processing is the main limitation with local agents. I also have a 128 GB M4 Max. How is the prompt processing on long prompts? processing the system prompt for Goose always takes quite a while for me. I haven't been able to download the 120B yet, but I'm looking to switch to either that or the GLM-4.5-Air for my main driver.
You mentioned "on local agents". I've noticed this too. How do ChatGPT and the others get around this, and provide instant responses on long conversations?
Not getting around it, just benefiting from parallel compute / huge flops of GPUs. Fundamentally, it's just that prefill compute is itself highly parallel and HBM is just that much faster than LPDDR. Effectively H100s and B100s can chew through the prefill in under a second at ~50k token lengths, so the TTFT (Time to First Token) can feel amazingly fast.
Using LM-Studio as the frontend and Playwright-powered MCP tools for browser access. I've had success with one such MCP: https://github.com/instavm/coderunner It has a tool called navigate_and_get_all_visible_text, for example.
{kind=link}